SQL UNION, INTERCEPT, EXCEPT with Examples
In our previous SQL Joins tutorial, you mastered the art of combining data from multiple tables horizontally. In this tutorial, we'll explore , which combines data vertically.
We'll also cover related SQL commands like and which help us identify commonalities and differences in our datasets.
UNION and UNION ALL in SQL
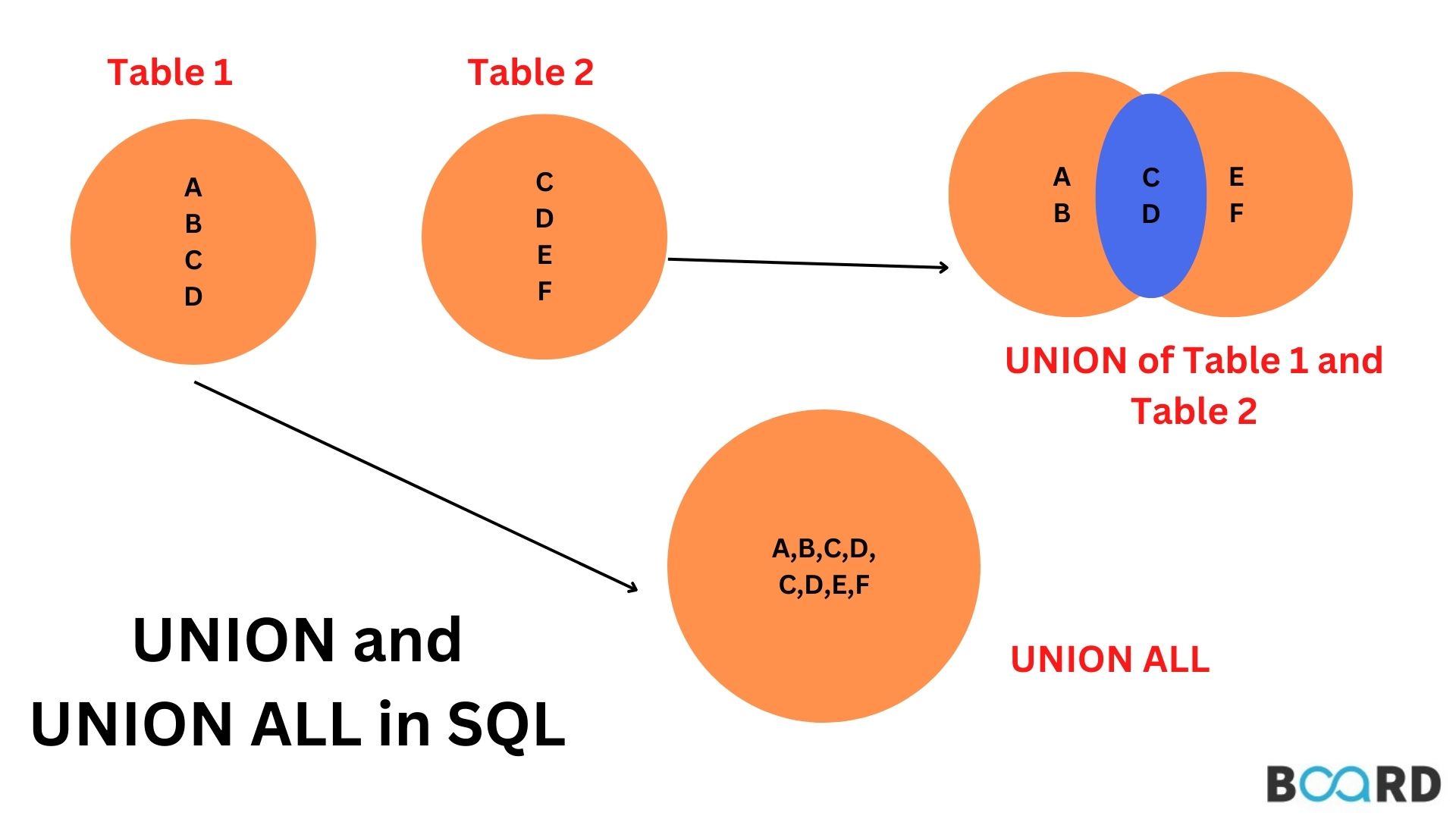
In SQL, and and are operators used to vertically concatenate two or more results.
The key difference between and is:
- UNION ALL keeps everything, including duplicates.
- UNION removes duplicates, so you get only the unique items.
To ensure the correct use of and , remember to follow these rules:
- The number of columns in each statement must match.
- The data types (e.g. INT, VARCHAR, DATETIME, etc.) of the columns must match.
- The columns selected in both statements must be in the same order.
Let's look at a SQL query that uses these commands.
UNION ALL Example
As mentioned earlier, combines results from two or more statements, but here's the twist: it includes all values, including duplicates.
To see this in practice, imagine you have two lists of ingredients for different cake recipes 🍰, stored in two different tables called and . You're planning your shopping trip and you want to combine these shopping lists so you can buy all the ingredients you need.
Here's the table with 6 ingredients:
| ingredient |
|---|
| Flour |
| Sugar |
| Eggs |
| Milk |
| Vanilla Extract |
| Salt |
Here's the table with 6 ingredients:
| ingredient |
|---|
| Flour |
| Sugar |
| Eggs |
| Cinnamon |
| Nutmeg |
| Salt |
We can use to combine the two ingredient lists:
This generates the following output:
| ingredient |
|---|
| Flour |
| Sugar |
| Eggs |
| Milk |
| Vanilla Extract |
| Salt |
| Flour |
| Sugar |
| Eggs |
| Cinnamon |
| Nutmeg |
| Salt |
Using , you get all ingredients from both recipes, including duplicates.
Now, let's apply these concepts to the Goodreads Book dataset you've worked with in the SQL Joins tutorial.
In this example, we retrieve a total of 40 books. This is because we're using which combines the results, including duplicates. If you examine the sequence, you'll notice duplicates for each .
UNION Syntax and Example
also combines results from two or more statements, but here's the twist: it gives you a list of unique values without duplicates.
Let's apply the operator to our earlier cake ingredients dataset:
Here's the output:
| ingredient |
|---|
| Flour |
| Sugar |
| Eggs |
| Milk |
| Vanilla Extract |
| Salt |
| Cinnamon |
| Nutmeg |
Do you see how this is a list of all the ingredients from , along with the unique items (Cinnamon, Nutmeg) from .
Let's now put these ideas to work using the Goodreads Book dataset.
Running this code returns a count of 20 books. Why? Because we're using which removes duplicates. In the result, you'll find no duplicate entries.
Tricky UNION SQL Interview Question Asked By Amazon
If you're feeling brave, try to attempt this tricky Amazon SQL Interview Question which makes use of / operators.
Your given the following Amazon table, and asked to maximize the number of items it can stock in a 500,000 square feet warehouse based on how much space each item in inventory takes:
| item_id | item_type | item_category | square_footage |
|---|---|---|---|
| 1374 | prime_eligible | mini refrigerator | 68.00 |
| 4245 | not_prime | standing lamp | 26.40 |
| 2452 | prime_eligible | television | 85.00 |
| 3255 | not_prime | side table | 22.60 |
| 1672 | prime_eligible | laptop | 8.50 |
You'll want to calculate the total square footage and the number of items for both prime and non-prime items as separate groups, and then use to combine the results into one result.
INTERSECT in SQL
The SQL operation is like finding common elements between two lists.
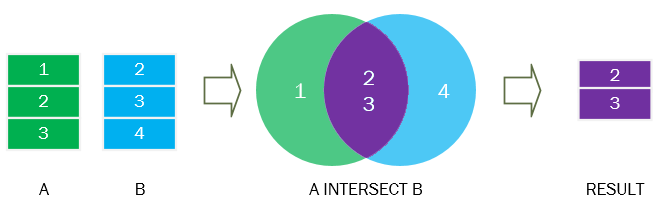
Imagine you have a columns of numbers in two different tables, and you want to know which numbers appear in both tables.
For example: List 1: 2, 4, 6, 8, 10 List 2: 4, 5, 8, 10, 15
When you use operator on these two lists, it gives you the numbers that are in both lists, which in this case would be 4, 8, and 10. It removes duplicates, so you get a clean list of common elements between two different tables.
INTERSECT SQL Syntax
Using the same cake ingredients data as before, imagine you want to know which ingredients are common between the two recipes. Here's the SQL query you'd write:
In this case, the common ingredients are: Flour, Sugar, Eggs, and Salt, so here's what the output would look like:
| ingredient |
|---|
| Flour |
| Sugar |
| Eggs |
| Salt |
Important rules for operator in SQL:
- The number of columns selected in both statements must be the same.
- The data types of the corresponding columns in both statements must be compatible.
- The columns you select in both statements should have the same order.
INTERSECT Example Query
Suppose you want to identify and retrieve order IDs that represent orders with two or more books that have been successfully delivered. Here's how you can do it using the and tables from the Goodreads Books dataset:
In this example, you'll get a result of 5 order IDs which represent orders that have deliveries with two or more books.
EXCEPT in SQL
The SQL statement is like a filter that helps you find records that are unique to one set of data when you have two sets of data.
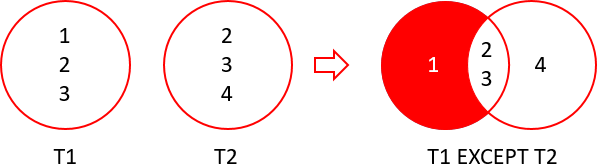
When you use the statement on the ingredient lists below, it gives you the ingredients that are in Recipe 1, but not in Recipe 2.
EXCEPT Syntax
Here are the recipes for your reference: Recipe 1 (6 items): Flour, Sugar, Eggs, Milk, Vanilla Extract, Salt Recipe 2 (6 items): Flour, Sugar, Eggs, Cinnamon, Nutmeg, Salt
In this case, the ingredients in Recipe 1 that are not in recipe 2 are: Milk and Vanilla Extract, so you'd get the following output:
| ingredient |
|---|
| Milk |
| Vanilla Extract |
Conditions for using the statement in SQL:
- The number of columns and their order in the statements must match between the tables.
- The data types of corresponding columns in both tables should either be the same or compatible.
EXCEPT Example
Now, let's find orders that have been placed but not delivered using the Goodreads Book dataset.
The result will be a list of order IDs that have been placed but not yet delivered.
Except Practice Exercise: FB SQL Interview Question
Try using to solve the FB SQL interview question, where you're given two tables containing data about Facebook Pages and their respective likes (as in "Like a Facebook Page"), and are asked to return the IDs of the Facebook pages that have zero likes.
Bringing It All Together
To sum it up:
- combine results horizontally.
- and stacks two or more results vertically.
- identifies common rows between two or more results.
- finds unique rows in the first query, but not present in the second query.
What's Next: SQL BEST PRACTICES
Congrats, you've learned pretty much every major SQL keyword. Now, it's time to learn some best practices for writing clean, well-styled SQL.
WRITE CLEAN SQL
Next Lesson
WRITE CLEAN SQL 🧼